16.1 Discovering Heuristics with Answer Set ProgrammingAnswer set programming, the topic of the previous chapter, has an interesting application beyond single-player games, namely, to discover useful properties of games written in GDL. You can use it to find latches, for example. Recall from Chapter 12 that a latch is a proposition that, when it becomes true (respectively, false), stays so for the rest of the game. To check that a state feature has this property, you first replace the given clauses for the initial state by the following ASP rule.
This fact acts as a state generator because it supports any base proposition to either be true or not at time 1. The missing number after the closing curly bracket indicates that a model can contain arbitrarily many elements from the set. We also stipulate that all players choose one legal move at time 1.
Now suppose that we want to verify an arbitrary base proposition p to be a positive latch, that is, to stay true once it becomes true. This is achieved by trying to find a counter-example, that is, a model in which p is true in one state but not so in the next state.
Finally, we need to filter out all models without such a counter-example as per the constraint below.
Every model that an ASP system will generate is a counter-example to the hypothesis that p cannot revert back from true to false. In other words, if the solver produces no answer, then you have checked that the proposition is in fact a latch. This argument involves double negation but is perfectly valid. In order to check that a proposition cannot revert back to true once it became false, you just need to replace the above by
Note that you only need two time points for this proof technique, which is one of the reasons why it is very viable in practice.
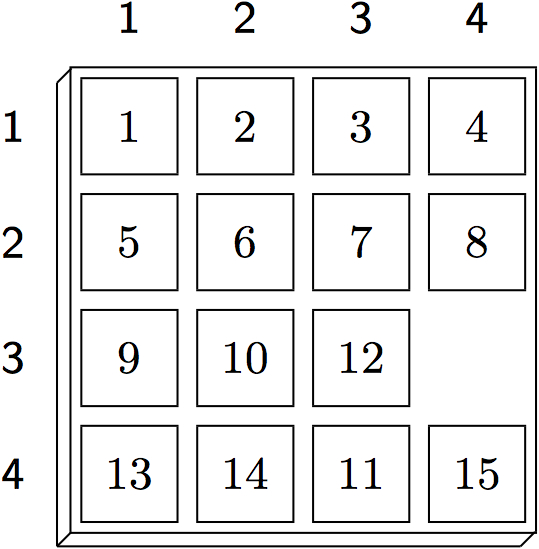
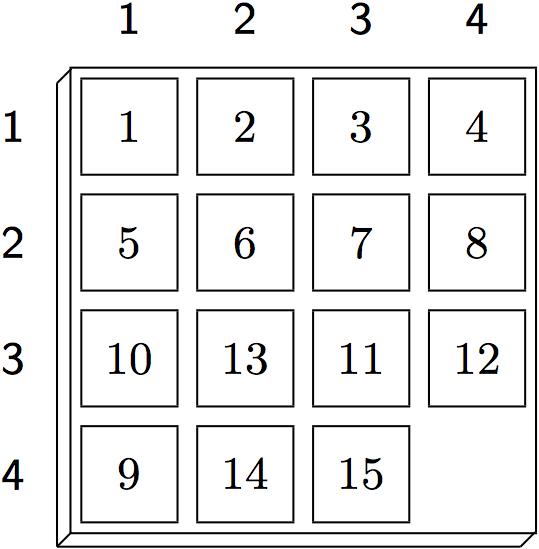
16.2 Goal HeuristicsGoal heuristics are based on the idea to evaluate intermediate positions according to their estimated distance to a goal - the closer a state is to our player's goal, the more promising it is. A good distance measure is often indicative of the quality of domain knowledge that a player has. In general game playing, players begin with knowing nothing of their goal besides the pure logical description. But this information alone suffices to create a basic distance measure. Fuzzy Logic helps us to define it. The main idea is to equate distance with the degree to which a given state satisfies a goal formula. As a motivating example, consider a popular single-player game. 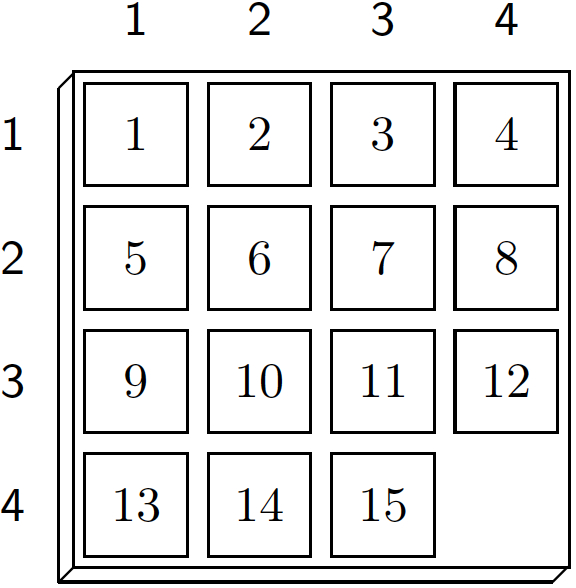
Suppose the GDL description of this game includes the following rule to define the goal.
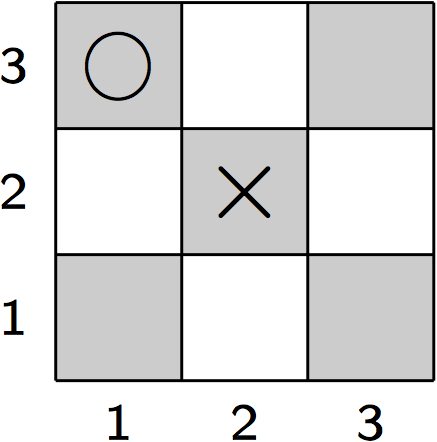
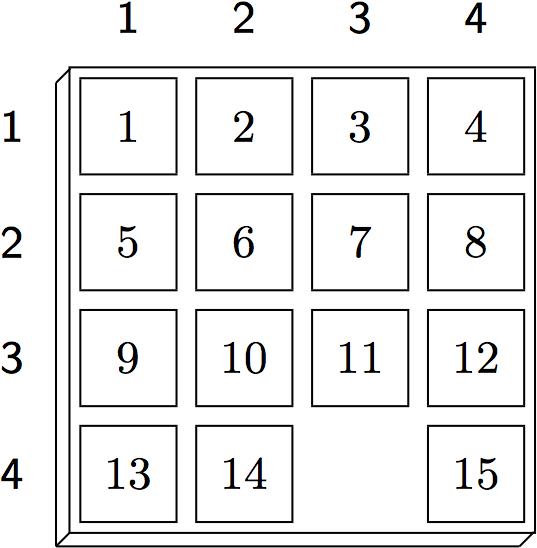
In Fuzzy Logic, the degree to which a conjunctive formula is satisfied is proportional to the number of conjuncts that are true. Hence, an intermediate position in the 15-puzzle will be judged by the number of tiles that are in the correct place. While not a perfect distance measure, it can be successfully employed as the sole parameter of the evaluation function in a depth-limited search with the effect that the player prefers moves that bring it closer to the goal configuration. 16.2 Fuzzy LogicTo implement a Fuzzy Logic-based goal heuristics, we first need to fix a truth value τ with 0.5<τ<1. When evaluating a GDL formula against a given state S, value τ will be assigned to all atoms true(p) for which p holds in S. Conversely, 1-τ will be assigned to any atom true(p) whose argument p does not hold in S. Consider, for example, a random Tic-Tac-Toe position. 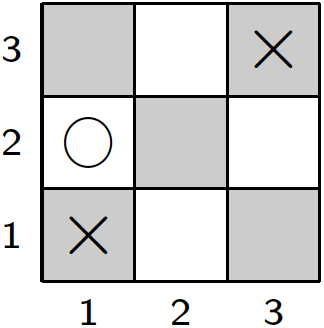
This state determines the truth values for three selected features shown in the table below, where τ has been set to 0.9.
For the evaluation of compound formulas in Fuzzy Logic, we need to also decide on a so-called t-norm. A t-norm (for: triangular norm) is a function T : [0,1] × [0,1] → [0,1] that is used to compute the truth value of a conjunction. (As a triangular norm the function must satisfy T(x,z)>T(y,z) whenever x>y and z>0.) A common and simple t-norm is given by the multiplication of the two arguments. For example, by multiplying the individual truth values taken from the table above we can determine the truth value of the conjunction in the formula shown below.
The resulting value is 0.081. This can be interpreted as the degree to which the body of the clause is satisfied in the state of Figure 16.3. Evaluating Complex FormulasAny t-norm is extensible to an evaluation function for arbitrary formulas with negation (~) and disjunction (|). For our example t-norm, computing the truth value of a compound formula follows the recursive definition shown below.
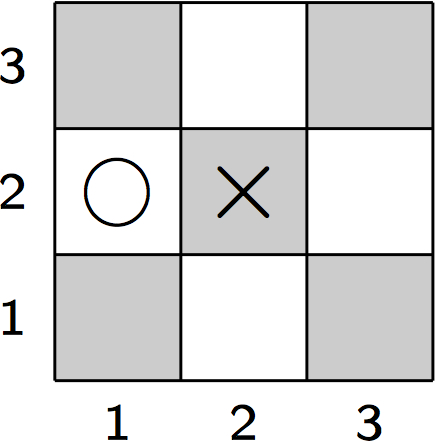
The function for the disjunction can be used for the evaluation of an atom that is defined by more than one rule. Consider, for example, the two rules defining a diagonal in Tic-Tac-Toe.
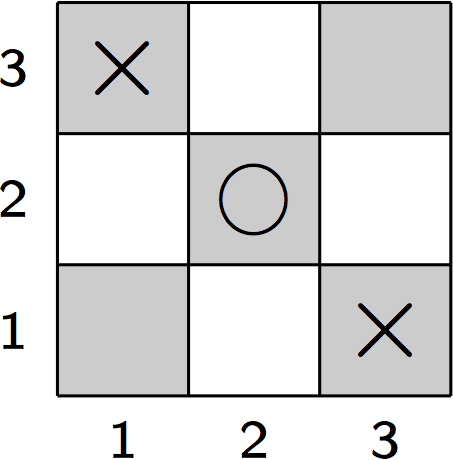
The body of the second clause evaluates to 0.13 = 0.001 in the position shown in Figure 16.3. Together with the value for the body of the first clause, 0.081, we obtain 0.081+0.001-(0.081⋅0.001) = 0.081919 for the truth value of diagonal(x). Analogously, we can use the rules for row(M,x) and column(N,x) to compute the truth values for each of their instances, that is, where M,N ∈ {1,2,3}. The resulting values can then be combined into the overall truth value for line(x). Again, this means to compute a disjunction from all instances of all rules for this predicate,
For our example position from Figure 16.3 we thus obtain a truth value of 0.116296 for line(x). In a similar fashion, we can compute the truth value for line(o) for the same position as 0.023797. According to the rule,
we can now compute the degree to which goal(white,100) is satisfied.
Finally, for games with more goal values than just the maximum of 100, we can compute a weighted average over all goal formulas and use the Fuzzy Logic function for disjunction to obtain a single number for the goal heuristics. In Tic-Tac-Toe, where the two positive goal values are 50 and 100, respectively, we compute the weighted average for white as shown below.
With truth(goal(white,50)) = (1 - truth(line(x))) ⋅ (1 - truth(line(o))) = 0.862674 according to the rule
this altogether results in a goal heuristics value of 49.589684 for the position shown in Figure 16.3. 16.3 Using the Goal HeuristicsThe primary use of the Fuzzy Logic goal heuristics is to evaluate leaf nodes during a game tree search. To see the heuristics in action, we can apply it to all successor states of the initial position in Tic-Tac-Toe to see which of the possibilities for placing the first mark looks most promising. 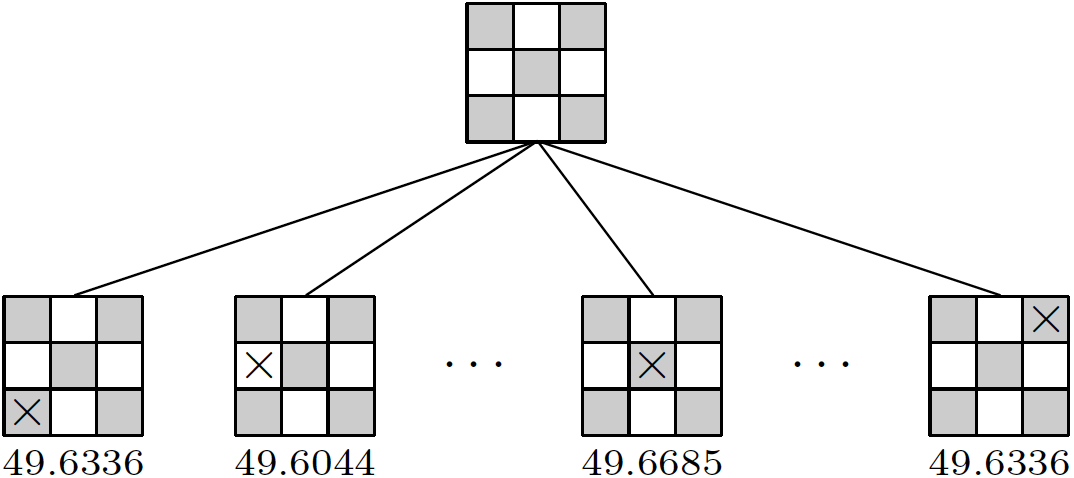
Without any search beyond the first ply, it follows that the center square is the best move according to the goal heuristics. Moreover, a cell in the corner is deemed more valuable than a non-corner border cell. Computing the fuzzy truth values for auxiliary atoms, such as line(x) or goal(x,100), requires to generate all relevant instances of the rules that define these atoms. This can be easily accomplished with the help of the domain analysis described in chapter 14. The domain graph for Tic-Tac-Toe depicted in Figure 14.2, for example, tells us which instances of the rules for line(X) shown below need to be considered when computing the fuzzy truth value of line(x) in any given situation.
16.4 Optimizations and LimitationsWhen computing the fuzzy truth value of a defined predicate, atoms in the body of a rule can be treated differently if their truth is independent of the current state. Examples include instances of the keywords role and distinct as well as every auxiliary predicate whose definition does not depend on keyword true. Any such state-independent atom can be assigned truth value 1 (if it is true) or 0 (if it is false) rather than τ or 1-τ. So doing simplifies the computation and also leads to sharper distinctions between different positions. The strict application of our example t-norm for the goal heuristics can have the practical disadvantage of approaching 0 for large conjunctions even when each conjunct is true. The goal predicate in the 15-puzzle shown in Figure 16.2, for instance, still has a low degree of τ15 = 0.915 = 0.20589 after the final goal position has been reached. In practice it is therefore useful to introduce a threshold θ that satisfies 0.5 < θ ≤ τ. This threshold can be used to ensure that a true formula always has a truth value greater than 0.5. To do so, we just need to slightly extend the computation of the fuzzy truth values for complex formulas.
The better a heuristics can distinguish between different states, the more useful it is for evaluation functions. The multiplication t-norm allows for little flexibility in this regard. A much wider range of t-norms is captured by the so-called Yager family. Each t-norm from this family is given for 0 ≤ q ≤ ∞ by
Any function S that is used to define a Yager t-norm T also serves as the corresponding computation rule for disjunctions. General game-playing systems that use these t-norms can adjust parameter q as well as the basic truth value τ depending on the complexity and structure of the goal formulas for different games. LimitationsThe Fuzzy Logic-based goal heuristics can be very useful for games whose goal, broadly speaking, is reachable through achieving successive sub-goals. This extends well beyond obvious examples like the 15-puzzle shown above. If, for instance, the aim is to eliminate all of your opponent's pieces or to occupy all locations on a board, and if this can be achieved successively, then goal heuristics can provide a useful guidance for a depth-limited search. A limitation of the simple goal heuristics is not to take into account how difficult it is to extend a partial solution to a complete one, or even if that is possible at all. In Tic-Tac-Toe, for example, every row, column, or diagonal with exactly two of our player's markers has the same fuzzy truth value, no matter whether the remaining third square is still free or already blocked. A possible solution could involve the concepts of latches and inhibitors (cf. Chapter 12). A proposition that is inhibited by an active latch can always be assigned truth value 0 because, by definition, it will never become true later in the game. Simple goal heuristics moreover generally fail to provide useful information for games with specialized goals like, for example, checkmate, whose logical definition alone does not allow to determine the degree to which it is already satisfied in an intermediate position. Exercises
|